主讲人:Ken(何琨)| NVIDIA开发者社区经理
张康 屈鑫 编辑整理
量子位 出品 | 公众号 QbitAI
7月21日,量子位联合NVIDIA英伟达举行了线下交流会,跟现场近百位开发者同学共同探讨了深度学习服务器搭建过程中可能出现的问题,交流了在开发中的实战经验。

本场活动主讲人为NVIDIA英伟达开发者社区经理Ken(何琨),拥有7 年 GPU 开发经验,5 年人工智能开发经验。在人工智能、计算机视觉、高性能计算领域曾经独立完成过多个项目,并且在机器人和无人机领域,有过丰富的研发经验。
曾针对图像识别,目标的检测与跟踪等方面完成多种解决方案,作为主要研发者参与GPU版气象模式GRAPES。

活动现场座无虚席,交流环节也反应热烈,线上聚集了千逾感兴趣的小伙伴观看现场直播。
应读者要求,量子位将现场内容整理成文,与大家分享。
深度学习服务器
深度学习发展已经历经很多年。现在的相关算法已经是二三十年前的理论,或者说相关数学算法和模型都没有太大变化。
为什么到最近几年,深度学习才真正火起来。因为在这个时间段,我们的计算能力达到了和深度学习理论对应的水平。
我们在用神经网络的时候,为什么中间那些隐藏层原来不能用,就是因为我们原来的计算能力、CPU达不到相对应的水平。
2007年NVIDIA提出了CUDA这样的方法和工具,为开发者进行高性能计算,或者一些更深的工作的时候,提供很多帮助。随着深度学习技术的发展,我们发现GPU也很适用于深度学习的工作。
今天概括讲三个比较重要的内容:第一是深度学习,也就是模型的训练;第二是在训练中的样本管理;第三是训练模型的部署。这是深度学习完整流程的三个重要部分。
有很多同学问我,NVIDIA的算法的一些工具,是开源的吗?NVIDIA很多是不开源的,但是不开源的东西不代表不可以用。下图所示的工具,都可以免费使用,包括一些专用的框架,支持几乎市面上常用的所有开源的深度学习框架。

对框架之下的底层内容又提供了计算服务,包括一些集成好的计算库。在很早的时候,用CUDA去做一些计算之前,需要学 CUDA C、CUDA Fortune、CUDA C++等等,最近几年还推出了CUDA python。
我们当初学CUDA的时候,觉得可能需要花半年的时间,才算真正学会了一个东西。而在现在这样技术发展非常快的时代,已经不需要把底层研究那么透,可以用工具来完成一些工作。
NVIDIA在深度学习这个领域提供了一些训练的库和工具,今天我会针对这些工具跟大家分享。
现在整个服务器里的硬件产品,大家接触更多的可能是Tesla系列,其实GeForce系列也可以拿来做实验,也能得到一个不错的效果。
硬件配置
如果我们想搭建一个GPU服务器,主要是硬件配置,硬件配置相关参数如下图。

Memory这块,32-64GB为宜,对服务器来说不算很大,但是也能够有一两个层次的区分。很多时候我们要处理样本,要对GPU进行一个调度,这个时候内存这块是个其实一个非常重要的问题,在一定数量级的计算上,这么大的内存是一个基本标准。
硬盘的配置上,如果低于上图的这个数值,我们在做深度学习开发的时候,在存储模型和样本的时候可能就会相对紧张。
接下来说电源和网络接口,这两个之前很容易忽略,但是非常重要。选择电源的时候,选2000w是因为可能有多个GPU并行的时候,在一个板上插很多GPU的时候,电源必须要支持,其次是选用冗余电源,如果突然断电的情况发生,还能坚持一下。
然后是网络接口。咱们自己在做实验的时候,难免去找一些免费的图片样本集等等,网络接口稍微大一点就非常省事。
整个的硬件配置建议就是这样。
软件配置

而在软件系统里边的配置,整个系统首先最好是Linux。有同学可能会问Windows的情况下是否支持,Windows系统在某些情况下是支持的,但是更多的情况下,在做深度学习开发的时候,还是尽量要往Linux上套一套。
我自己更喜欢的系统是Ubuntu,Centos等系统大家喜欢也可以去用,NVIDIA也是支持的。
这里有个小建议,如果是初学者,不是很了解这些配置,那版本可选低一点。稍后后面会给大家介绍如何配环境,是以 16.04这个系统的版本为基准。大家需要注意的一个问题:选择高级的版本,可能会有一些新的库不匹配的情况。
接下来说安装驱动的问题。我建议大家直接去官网下载;不行的话,如果比如在Ubuntu这样的,直接用系统自带的安装就行;还是不行的话,在CUDA里,也会自带一个驱动,按照最新的安装就好。
安装完驱动后,接下来介绍一下深度学习开发工具:CuDNN、TensorRT、CuBLAS、DeepStream。
TensorRT是在部署阶段,一个加速inference的工具,目前为止4.0版本已经支持包括C++和python接口。而且它支持Caffe、TensorFlow等主流的框架,而且通过一个ONNX网络模型的格式,可以支持PyTorch,Caffe2等等。我自己在测试这个工具的时候发现,拿任何一个框架,同样的模型,相同的数据测试它是最快的。
接下来是CuDNN,它跟TensorRT是一对,我们可以理解为CuDNN是提供了训练时候的库。用CuDNN之后的训练速度,平均能快到4到5倍以上。
TensorRT是inference,CuDNN是training。
最后说一下DeepStream的发展。这个工具刚到2.0,是目前一个非常新的工具。它的系统是在视频编解码的过程当中,就把inference这个过程做了。这样就省去了时间。
最开始的时候说过,深度学习的完整流程有三个大的部分:样本的管理、模型的训练和模型的部署。DIGITS是管理前两个过程的重要工具。
具体的工具&安装过程
现在给大家介绍一下具体的工具,和安装过程。
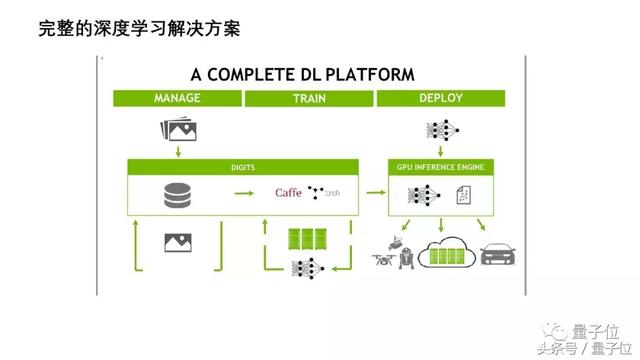
这张图是一个完整的深度学习解决方案。
样本的管理中,可能有很多图片或者音频视频资料,对这些的管理就依赖于服务器本身的处理能力。当然也可以用GPU进行一些加速,我需要主要介绍训练和部署这两个阶段,这两个阶段有一个很根本的不同:训练的时候是在线的模式,模型要一步一步地迭代,模型是在不断更新的,如果在这个过程当中发现哪里的参数达不到心理预期了,或者是出现一些异常的时候,马上可以更改,调整网络模型,或者调整样本。
而在部署阶段,整个的模型是以离线的方式运用,不可能在推理的过程当中更改样本。比如智能的硬件设备,它的识别速度要求都非常高,而在部署到这些产品的时候,计算能力是极其有限的。而在这种计算能力有限的情况下,我们还要求更高的计算速度,这个时候就需要我们采用更好的inference算法。在这里,我推荐大家可以尝试TensorRT这个inference工具。
搭建服务器的流程
接下来介绍一下搭建服务器的整体流程。

从系统开始,安装CUDA之后安装CuDNN,接下来是TensorFlow和Caffe两个框架,然后是TensorRT,最后是DIGITS的完整流程。
CUDA的安装

首先是CUDA的安装。
如果是初学者,建议直接下载.deb文件,不要用.run安装。因为首先流程很简单,其次整个安装的流程中一些备文件位置也都详细提供,省去很多麻烦。如果大家觉得自己网络好,还有一种network的安装方式,也可以尝试。
CuDNN的安装
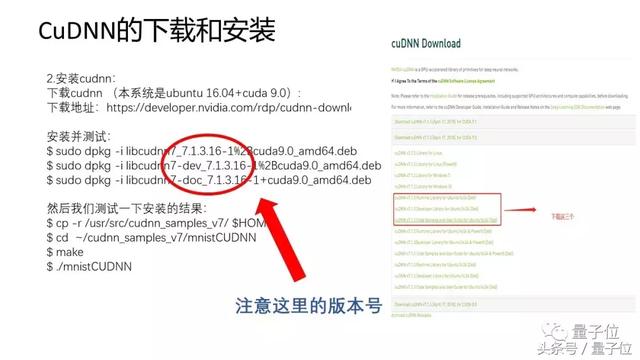
接下来下载CUDA,按照流程走下来。需要注意的是:1、不要忘了在环境变量中把路径加进去。2、在安装Caffe和TensorFlow的时候,如果选择使用CUDA或者CuDNN在系统,记得加上lib的库。
然后是下载CuDNN,建议大家都安装CuDNN,安装之后速度会提升很多。
其中需要注意的是CuDNN的版本号,版本号一定要记住,后续安装其他一些工具的时候都会涉及到。在做Linux开发的时候,不只是在CUDA或者GPU开发,这样的工具,一定要注意安装的版本号。如果是初学者,为了省去一些麻烦,最好用大版本号。
TensorRT的安装

接下来是TensorRT的下载和安装。同样也是建议直接下载.deb。
TensorFlow & Caffe的安装


最后还有两个框架:Tensorflow和Caffe。
TensorFlow的框架,推荐大家使用TensorRT,能够加速推理。
Caffe的安装是基于CuDNN和CUDA的版本。有一点可能需要注意:Caffe的版本,推荐大家用0.15的版本,这个版本跟标准Caffe版本在最底层有一点不同,所以能做到更全面。
DIGITS

最后说一下DIGITS这个工具,上图是DIGITS的基本界面。
做深度学习训练的时候,会用到样本的管理,用个人服务器去管理内容的时候,通常情况下没法可视化。如果只开一个终端的话,会有些卡顿,效果很不好。这个工具能够提供各种各样的接口,包括如何组织样本,或者查看样本当中的一些分布。
除此之外DIGITS里还有一些预训练的模型,比如里边已经有了的GoogleNet和AlexNet,只需要再把样本做好就行。
如果需要自己定义网络模型,直接把网络结构,复制到DIGITS里就好。
最后介绍一下TensorRT的工具,它是一个加速工具。NVIDIA在建立TensorRT这个项目之初是把它定义为一个GPU Inference Engine这样一个名字。
整个工具的机制是:输入一个训练好的神经网络模型,这个模型可以是Caffe、Tensorflow或者PyTorch,输入完后会在里面自动优化模型,进行加速。
而我们自己加速模型的时候,需要对模型进行剪裁,对模型参数进行一些不必要的一些筛选和优化。或者针对模型写一些解析器,在解析器里自动裁剪、加速。在这个过程中,会浪费很多时间。
接下来是输出一个可执行的推理引擎,然后可序化这个可执行推理引擎,把序列化好的一个文件放入虚拟引擎,向引擎里输入一张图片或者语音实例,最后就能输出一个结果。
总结

总结一下,要搭一台自己的服务器,需要选择好硬件产品,不一定要选最贵的或者大的,而是根据自己的需求,是需要更大的显存还是更强的计算能力,还是对带宽有要求等等,包括性价比,也是考虑因素。
然后是配置软件环境,如果能自己配置好一个软件环境,包括安好的拓展、框架,就可以直接实验了。
后边的管理系统和加速工具,就是代表真正生产力的工具。
Q&A
DIGITS是否收费,我们如何使用?开源的Jupyter Notebook能用吗?
DIGITS是免费的,而且开源。
开源的Jupyter Notebook可以用。
虚拟机里怎么用CUDA?
我在很早之前用过虚拟机里的CUDA,但是使用起来太麻烦了,不建议大家在虚拟机里使用CUDA,但是确实是可以用的。会出一些很细小的bug,而有些 bug本身并不是写的问题,并不是代码写错,可能是虚拟机底层机制通讯的问题。
做优化的时候,只优化GPU的计算,会不会对网络结构,或者说最后的精度有影响?
会有一定影响,但是这个影响在决断和服务范围内。因为CRD本身有一个机制:控制阈值与进度的影响。本身CRD的核心思想就是稍微降低一点的精度,大量提高速度。CRD本身的作用是部署在产品端,它要求更快的速度的问题。
学习资料
点击“阅读原文”,可直达交流会视频回放界面。
在量子位微信公众号(QbitAI)对话界面回复“0801”,即可获得完整PPT下载地址,及视频回放地址。
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
NVIDIA英伟达:深度学习服务器搭建指南|交流会笔记http://t.jinritoutiao.js.cn/eD2asa/



