【体积减半画质翻倍,他用TensorFlow实现了这个图像极度压缩模型】
体积小,但清晰度高。
就有这么一种基于生成式对抗网络(GAN)的极度图像压缩框架,经它之手的图像虽然体积被压缩不少,但分辨率着实感人。和同类框架相比,它的效果尤为惊艳。

△ 此算法(2379 Bytes)和BPG(2565 Bytes)画质对比

△ 此算法(2379 Bytes)和WebP(6066 Bytes)画质对比

△ 此算法(2379 Bytes)和JPEG2000(2447 Bytes)画质对比

△ 此算法(2379 Bytes)和原图画质对比
就是这样一个体积小一半但画质高一倍的算法,自上个月在arXiv出现后便引发关注。
看了研究论文Generative Adversarial Networks for Extreme Learned Image Compression后,网友大呼希望这群来自苏黎世联邦理工学院的程序员们开个源。

△ 作者团队
好消息是,近日,Github网友Justin-Tan用TensorFlow实现了这项研究,我们一起看看这个爆火的压缩大法实现~
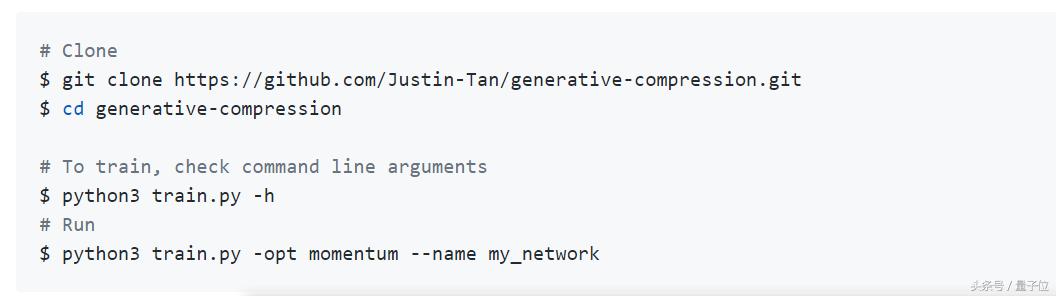
实现用法及结果
实现的第一步得准备工具,也是就是TensorFlow 1.8。
TensorFlow 1.8地址:
https://github.com/tensorflow/tensorflow
在batch size是1的情况下训练,每经过一定的步数中 (默认值为128),重建的样例/summary就会被定期写入,每10次迭代后保存检查点。
这些全局压缩的图像来自于Cityscapes中leftImg8bit数据集,总体来看,效果还比较好。

△ C=8 channel,多规格鉴别器
下图是量化的C=4、8、16 channel图像比较——
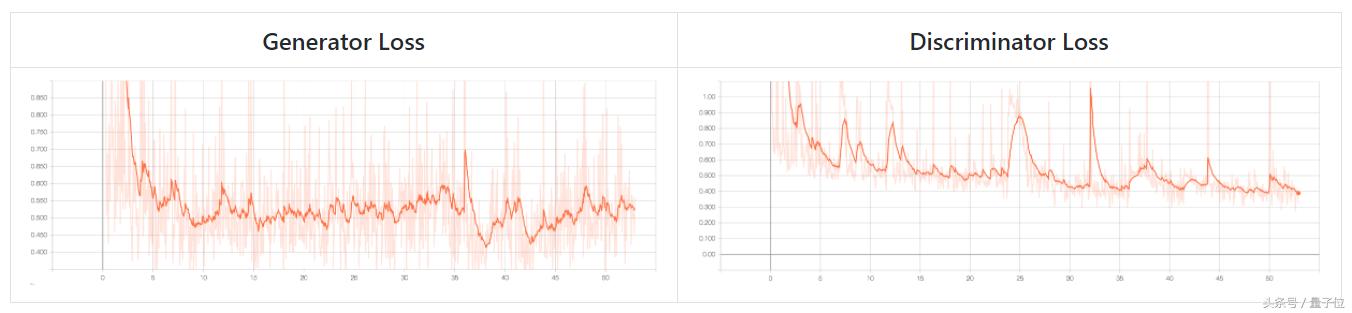
实现细节/扩展
你可以在下找到预训练模型,它在C=8的channel bottleneck和多规格鉴别器损失进行全局压缩。这个模型已经用Cityscapes中的leftIma8bit训练了64次。
这个网络的架构是基于论文 Perceptual Losses for Real-Time Style Transfer and Super-Resolution中的附录中提供的描述完成的,项目中最初提到的多规格鉴别器的损失是基于论文 High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs完成的。
如果你还想增加扩展,可以在Network分类下新写一个@staticmethod版块,类似下面这样:

如果想更改超参数和toggle feature,可在config.py中设置。
相关地址和资料
如果你对这个压缩大法感兴趣,这刚好有几份资料可以拿去用:
论文Generative Adversarial Networks for Extreme Learned Image Compression地址:
https://arxiv.org/pdf/1804.02958.pdf
项目首页:
https://data.vision.ee.ethz.ch/aeirikur/extremecompression/#publication
复现项目地址:
https://github.com/Justin-Tan/generative-compression
论文Perceptual Losses for Real-Time Style Transfer
and Super-Resolution地址:
https://cs.stanford.edu/people/jcjohns/eccv16/
论文High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs地址:
https://tcwang0509.github.io/pix2pixHD/
— 完 —



