【用TensorFlow基于神经网络实现井字棋(含代码)】
为了展示如何应用神经网络算法模型,我们将使用神经网络来学习优化井字棋(Tic Tac Toe)。明确井字棋是一种决策性游戏,并且走棋步骤优化是确定的。
开始
为了训练神经网络模型,我们有一系列优化的不同的走棋棋谱,棋谱基于棋盘位置列表和对应的最佳落子点。考虑到棋盘的对称性,通过只关心不对称的棋盘位置来简化棋盘。井字棋的非单位变换(考虑几何变换)可以通过90度、180度、270度、Y轴对称和X轴对称旋转获得。如果这个假设成立,我们使用一系列的棋盘位置列表和对应的最佳落子点,应用两个随机变换,然后赋值给神经网络算法模型学习。
井字棋是一种决策类游戏,注意,先下者要么赢,要么继续走棋。我们希望能训练一个算法模型给出最佳走棋,使得棋局继续。
在本例中,棋盘走棋一方“×”用“1”表示,对手“O”用“-1”表示,空格棋用“0”表示。图 6-9 展示了棋盘的表示方式和走棋:
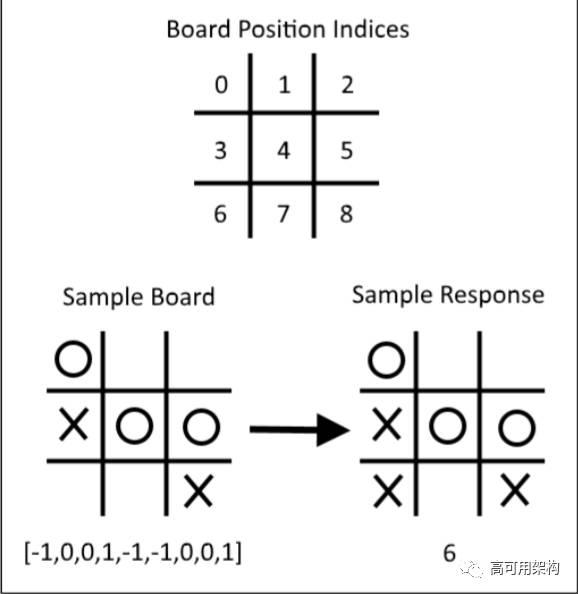
图6-9 展示棋盘和走棋的表示方式
注意,× = 1,O = -1,空格棋为 0。棋盘位置索引的起始位置标为 0。
除了计算模型损失之外,我们将用两种方法来检测算法模型的性能:第一种检测方法是,从训练集中移除一个位置,然后优化走棋。这能看出神经网络算法模型能否生成以前未有过的走棋(即该走棋不在训练集中);第二种评估的方法是,直接实战井字棋游戏看是否能赢。
不同的棋盘位置列表和对应的最佳落子点数据在 GitHub [1] 中可以查看。
动手做
1.导入必要的编程库,代码如下:
import tensorflow as tf
import matplotlib.pyplot as plt
import csv
import random
import numpy as np
import random
2.声明训练模型的批量大小,代码如下:
batch_size = 50
3.为了让棋盘看起来更清楚,我们创建一个井字棋的打印函数,代码如下:
def print_board(board):
symbols = [‘O’,’ ‘,’X’]
board_plus1 = [int(x) + 1 for x in board]
print(‘ ‘ + symbols[board_plus1[0]] + ‘ | ‘ + symbols[board_
plus1[1]] + ‘ | ‘ + symbols[board_plus1[2]])
print(‘___________’)
print(‘ ‘ + symbols[board_plus1[3]] + ‘ | ‘ + symbols[board_
plus1[4]] + ‘ | ‘ + symbols[board_plus1[5]])
print(‘___________’)
print(‘ ‘ + symbols[board_plus1[6]] + ‘ | ‘ + symbols[board_
plus1[7]] + ‘ | ‘ + symbols[board_plus1[8]])
4.创建get_symmetry函数,返回变换之后的新棋盘和最佳落子点,代码如下:
def get_symmetry(board, response, transformation):
”’
:param board: list of integers 9 long:
opposing mark = -1
friendly mark = 1
empty space = 0
:param transformation: one of five transformations on a board:
rotate180, rotate90, rotate270, flip_v, flip_h
:return: tuple: (new_board, new_response)
”’
if transformation == ‘rotate180’:
new_response = 8 – response
return(board[::-1], new_response)
elif transformation == ‘rotate90’:
new_response = [6, 3, 0, 7, 4, 1, 8, 5, 2].index(response)
tuple_board = list(zip(*[board[6:9], board[3:6], board[0:3]]))
return([value for item in tuple_board for value in item], new_response)
elif transformation == ‘rotate270’:
new_response = [2, 5, 8, 1, 4, 7, 0, 3, 6].index(response)
tuple_board = list(zip(*[board[0:3], board[3:6],
board[6:9]]))[::-1]
return([value for item in tuple_board for value in item], new_response)
elif transformation == ‘flip_v’:
new_response = [6, 7, 8, 3, 4, 5, 0, 1, 2].index(response)
return(board[6:9] + board[3:6] + board[0:3], new_response)
elif transformation == ‘flip_h’:
# flip_h = rotate180, then flip_v
new_response = [2, 1, 0, 5, 4, 3, 8, 7, 6].index(response)
new_board = board[::-1]
return(new_board[6:9] + new_board[3:6] + new_board[0:3],
new_response)
else:
raise ValueError(‘Method not implmented.’)
5.棋盘位置列表和对应的最佳落子点数据位于.csv文件中。我们将创建get_moves_from_csv函数来加载文件中的棋盘和最佳落子点数据,并保存成元组,代码如下:
def get_moves_from_csv(csv_file):
”’
:param csv_file: csv file location containing the boards w/responses
:return: moves: list of moves with index of best response
”’
moves =
with open(csv_file, ‘rt’) as csvfile:
reader = csv.reader(csvfile, delimiter=’,’)
for row in reader:
moves.append(([int(x) for x in row[0:9]],int(row[9])))
return(moves)
6.创建一个get_rand_move函数,返回一个随机变换棋盘和落子点,代码如下:
def get_rand_move(moves, rand_transforms=2):
# This function performs random transformations on a board.
(board, response) = random.choice(moves)
possible_transforms = [‘rotate90’, ‘rotate180’, ‘rotate270’, ‘flip_v’, ‘flip_h’]
for i in range(rand_transforms):
random_transform = random.choice(possible_transforms)
(board, response) = get_symmetry(board, response, random_transform)
return(board, response)
7.初始化计算图会话,加载数据文件,创建训练集,代码如下:
sess = tf.Session
moves = get_moves_from_csv(‘base_tic_tac_toe_moves.csv’)
# Create a train set:
train_length = 500
train_set =
for t in range(train_length):
train_set.append(get_rand_move(moves))
8.前面提到,我们将从训练集中移除一个棋盘位置和对应的最佳落子点,来看训练的模型是否可以生成最佳走棋。下面棋盘的最佳落子点是棋盘位置索引为6的位置,代码如下:
test_board = [-1, 0, 0, 1, -1, -1, 0, 0, 1]
train_set = [x for x in train_set if x[0] != test_board]
9.创建init_weights函数和model函数,分别实现初始化模型变量和模型操作。注意,模型中并没有包含softmax激励函数,因为softmax激励函数会在损失函数中出现,代码如下:
def init_weights(shape):
return(tf.Variable(tf.random_normal(shape)))
def model(X, A1, A2, bias1, bias2):
layer1 = tf.nn.sigmoid(tf.add(tf.matmul(X, A1), bias1))
layer2 = tf.add(tf.matmul(layer1, A2), bias2)
return(layer2)
10.声明占位符、变量和模型,代码如下:
X = tf.placeholder(dtype=tf.float32, shape=[None, 9])
Y = tf.placeholder(dtype=tf.int32, shape=[None])
A1 = init_weights([9, 81])
bias1 = init_weights([81])
A2 = init_weights([81, 9])
bias2 = init_weights([9])
model_output = model(X, A1, A2, bias1, bias2)
11.声明算法模型的损失函数,该函数是最后输出的逻辑变换的平均softmax值。然后声明训练步长和优化器。为了将来可以和训练好的模型对局,我们也需要创建预测操作,代码如下:
loss = tf.reduce_mean( tf.nn.sparse_softmax_cross_entropy_with_logits(model_output, Y))
train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss)
prediction = tf.argmax(model_output, 1)
12.初始化变量,遍历迭代训练神经网络模型,代码如下:
# Initialize variables
init = tf.initialize_all_variables
sess.run(init)
loss_vec =
for i in range(10000):
# Select random indices for batch
rand_indices = np.random.choice(range(len(train_set)), batch_size, replace=False)
# Get batch
batch_data = [train_set[i] for i in rand_indices]
x_input = [x[0] for x in batch_data]
y_target = np.array([y[1] for y in batch_data])
# Run training step
sess.run(train_step, feed_dict={X: x_input, Y: y_target})
# Get training loss
temp_loss = sess.run(loss, feed_dict={X: x_input, Y: y_
target})
loss_vec.append(temp_loss)
if i%500==0:
print(‘iteration ‘ + str(i) + ‘ Loss: ‘ + str(temp_loss))
13.绘制模型训练的损失函数,代码如下(对应的图见图6-10):
plt.plot(loss_vec, ‘k-‘, label=’Loss’)
plt.title(‘Loss (MSE) per Generation’)
plt.xlabel(‘Generation’)
plt.ylabel(‘Loss’)
plt.show

图6-10 迭代10000次训练的井字棋模型的损失函数图
下面绘制模型训练的损失函数:
1.为了测试模型,将展示如何在测试棋盘(从训练集中移除的数据)使用。我们希望看到模型能生成预测落子点的索引,并且索引值为6。在大部分情况下,模型都会成功预测,代码如下:
test_boards = [test_board]
feed_dict = {X: test_boards}
logits = sess.run(model_output, feed_dict=feed_dict)
predictions = sess.run(prediction, feed_dict=feed_dict)
print(predictions)
2.输出结果如下:
[6]
3.为了能够评估训练模型,我们计划和训练好的模型进行对局。为了实现该功能,我们创建一个函数来检测是否赢了棋局,这样程序才能在该结束的时间喊停,代码如下:
def check(board):
wins = [[0,1,2], [3,4,5], [6,7,8], [0,3,6], [1,4,7], [2,5,8],[0,4,8], [2,4,6]]
for i in range(len(wins)):
if board[wins[i][0]]==board[wins[i][1]]==board[wins[i][2]]==1.:
return(1)
elif board[wins[i][0]]==board[wins[i][1]]==board[wins[i][2]]==-1.:
return(1)
return(0)
4.现在遍历迭代,同训练模型进行对局。起始棋盘为空棋盘,即为全0值;然后询问棋手要在哪个位置落棋子,即输入0-8的索引值;接着将其传入训练模型进行预测。对于模型的走棋,我们获得了多个可能的预测。最后显示井字棋游戏的样例。对于该游戏来说,我们发现训练的模型表现得并不理想,代码如下:
game_tracker = [0., 0., 0., 0., 0., 0., 0., 0., 0.]
win_logical = False
num_moves = 0
while not win_logical:
player_index = input(‘Input index of your move (0-8): ‘)
num_moves += 1
# Add player move to game
game_tracker[int(player_index)] = 1.
# Get model’s move by first getting all the logits for each
index
[potential_moves] = sess.run(model_output, feed_dict={X:
[game_tracker]})
# Now find allowed moves (where game tracker values = 0.0)
allowed_moves = [ix for ix,x in enumerate(game_tracker) if
x==0.0]
# Find best move by taking argmax of logits if they are in
allowed moves
model_move = np.argmax([x if ix in allowed_moves else -999.0
for ix,x in enumerate(potential_moves)])
# Add model move to game
game_tracker[int(model_move)] = -1.
print(‘Model has moved’)
print_board(game_tracker)
# Now check for win or too many moves
if check(game_tracker)==1 or num_moves>=5:
print(‘Game Over!’)
win_logical = True
5.人机交互的输出结果如下:
Input index of your move (0-8): 4
Model has moved
O | |
___________
| X |
___________
| |
Input index of your move (0-8): 6
Model has moved
O | |
___________
| X |
___________
X | | O
Input index of your move (0-8): 2
Model has moved
O | | X
___________
O | X |
___________
X | | O
Game Over!
工作原理
我们训练一个神经网络模型来玩井字棋游戏,该模型需要传入棋盘位置,其中棋盘的位置是用一个九维向量来表示的。然后预测最佳落子点。我们需要赋值可能的井字棋棋盘,应用随机转换来增加训练集的大小。
为了测试算法模型,我们移除一个棋盘位置列表和对应的最佳落子点,然后看训练模型能否生成预测的最佳落棋点。最后,我们也和训练模型进行对局,但是结果并不理想,我们仍然需要尝试不同的架构和训练方法来提高效果。



