从Level 0到Level 5,自适应学习可分为哪些等级?

图片来源:摄图网
本文是胡天硕《揭秘自适应学习的背后原理》系列文章第二篇,第一篇为《一套自适应学习系统更应该包括那些环节?》。
当大家聊起AI与汽车的时候,第一个想到的是无人驾驶技术。当大家聊起AI与教育的时候,第一个往往想到的则是自适应学习。然而自适应学习就像无人驾驶一样,是分为不同的等级。较低等级的自适应学习几乎与AI无关,而最高等级的自适应学习没有一家公司能够完全做出来,是AI领域非常困难的问题。
今天我带着大家从最低水平的自适应学习,一直讲述自适应学习的最高等级。
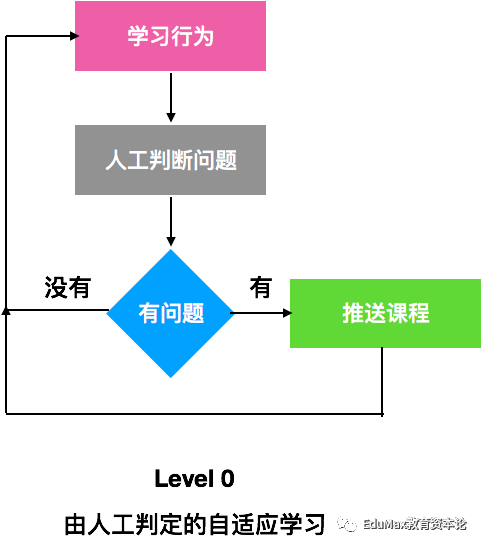
Level 0:基于纯人工的自适应学习
如果要做一款自适应学习的产品,我们先假设电脑是完全没有能力判断出学生的能力水平,而由老师来做判断,判断之后,由电脑来推送相应的课程。
1、英语作文批改
用户在网站上录入了自己的托福作文,提交后,作文被送到一个队列里等待人工的批注。老师收到了新的作文后,对学生作文的各个部分进行标注,哪些单词拼错了,用错了,哪些固定搭配错了,哪些语法有问题,文章结构有什么问题。批改完毕后,学生会收到老师的评价,和系统自动推送出的单词,语法,和结构课。从算法上来讲,逻辑很简单,总共会有不同的几种错误类型,和对应的课程,只要学生在作文里出现某种错误,就自动推这类课程。
2、一对一几何课
老师在一对一地个性化辅导一个同学,这时候给出一道几何题目让学生完成,学生通过手写的方式录入自己的答案,但是中间有几个过程问题。老师用手写批改后,在直播过程中的后台,记录了学生的知识漏洞,课后生成的学习报告里,会包括学生的知识点掌握情况,出现的错题,推荐做的同类题目。甚至,完全可以在直播的过程中,老师出什么题目,完全并不由老师决定,而是由系统自动出,老师每次只是给出评价学生到底出现哪些知识漏洞,是否要出一个更难的挑战?从算法上来讲,逻辑也非常简单,一道几何题出现的错误类型有限,可以为每道题目找难度更低和更高的几种题目,然后由老师决定是加大难度,减少难度,还是到下一个学习环节。
接下来我们让电脑来判断学生的对错。
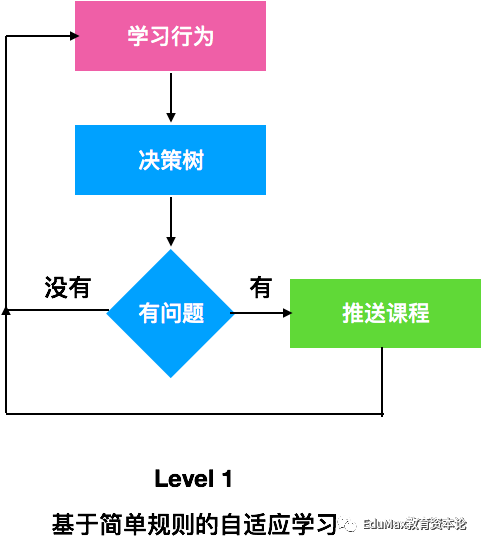
Level 1:基于简单规则的自适应学习
我们要在Level 0的基础上加入简单的条件判断,就可以实现最简单的自适应学习算法。基于规则的自适应学习,其实本质是决策树,适用场景是那些不去判断学生是否掌握某种知识,而是直接去判断学生的某种行为是否是不对的。
1、汽车模拟驾驶
学生闯红灯了,扣分,然后告诉学生,你要注意红绿灯。学生左转忘打转向灯了,扣分,然后告诉学生,你要记得打转向灯。学生超速了,扣分,然后告诉学生,你要注意自己行驶的速度。由于是电脑模拟驾驶,判断语句设计起来都并不复杂。这种情况,不仅适用于开车,也适用于开飞机,开挖掘机,等各种计算机可以模拟的情景。
2、智能健身矫正

通过可穿戴式或者是视频式的动作捕捉设备,能够获得学生在做深蹲,硬拉,平板支撑等一系列动作时各个关节的角度。当学生完成动作的过程中有角度超出规定值的时候,就提醒学生,你硬拉时背部不够收紧,臀部不够翘起。动作捕捉的技术和硬件虽然当前还未普及,但是实际上,判断姿态是否正确的算法并不是那么困难。这种情况,不仅适用于健身,还有各种球类,舞蹈,甚至器乐的基本功学习。
实际上学生的掌握程度,未必是那么黑白分明,对就是对,错就是错,接下来,我们需要在简单的决策树规则之上建立更好的自适应学习算法。
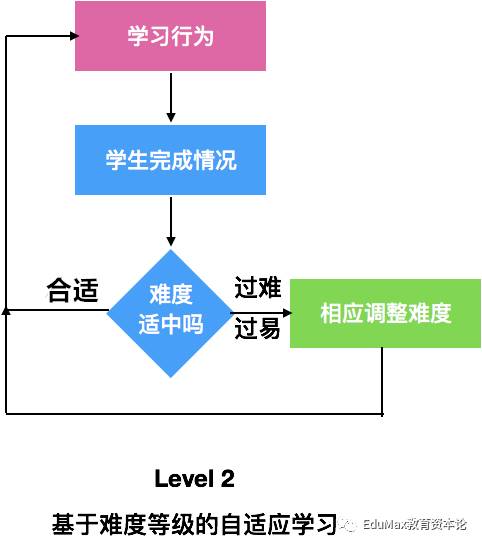
Level 2:基于难度等级的自适应学习
刚才我们在Level 1级的自适应学习里,通过学生的行为直接指出学生的问题。而拿开车的例子,同样两个人既不闯红灯,也不超速,但依然可能开除的体验非常不同——所谓有新手司机和老司机的区别。
如果我们不去规定,学生什么具体行为错了就推送什么相应课程,而是设计一套难度递增的课程,当学生完成得好的时候就加大挑战难度,当学生完成的有问题时,就相应减少难度。这就是基于难度等级的自适应学习。
1、英语分级阅读

一个学生是否能看懂一篇文章,背后的原因是非常多的。一个很难的单词,靠上下文,反而可能能猜测出来;几个简单的单词,组合成短语和搭配,可能完全意思就变了;甚至如果是因为专业问题,可能单词,短语,语法都完全看得懂,但依然不明白的现象也会发生。
所以国外提出了所谓的readability(可读性)的概念,儿童出版社将书籍按照大概的年龄段划分。教学的时候,虽然每一个孩子有他的真实年龄,但是可以通过阅读测试找到最合适他读的年龄段。一开始当书比较少的时候,可以由教育专家和老师来评定书籍的可读性,但随着要标注的书籍的增加,这件事情就必须由算法来完成。
国外readability的算法在wikipedia有讲述,以常见的Flesch-Kincaid等级为例,单词的平均音节数越多,段落里句子的长度越长,就认为文章越难读懂。例如高考听力的难度最难也就在10年级,高考阅读在12年级左右,托福雅思的阅读题可能会有18-19年级的压轴题。注意像Flesch-Kincaid这类把句子长度考虑进去的readability算法,对于缺乏标点符号的歌词或诗歌,还有标点符号过于频繁的对话型文章,都会有较大偏差,需要进行修正。
2、王者荣耀的天梯系统
在这里我们举一个非常有意思的学习例子,那就是手机游戏。像王者荣耀这类MOBA手机游戏,并不是自己去设计不同难度的关卡让用户进阶学习而是采用了天梯的方式,让水平近似的人在相同的段位PK,变相地提供了一个进阶的台阶。在排位赛的个天梯系统里,赢得多了就会遇到更强的对手,输得多了,就会遇到更弱的对手。虽然最终比赛的输赢不仅和个人的操作、意识和配合有关,还跟自己的队友,选择的英雄组合相比较对手是压制和被压制,还有运气有关。但是整体来讲,差一个大的段位(例如钻石和铂金),水平上一定会有明显的差距。
elo算法在围棋,国际象棋,是国际上评估水平高低的重要算法。与天梯系统不同,输赢的得分并不是固定的,而和你和竞争对手的差异有关的,如果你赢了水平比你强的人,你提的分数多,而他掉的分数多,如果你输了水平比你强的人,你掉的分数少,而他提的分数也少。感兴趣的可以参考这里。
基于难度的自适应学习算法的最大缺点是认为学生的学科掌握度是一个值——有点像把学生分为重点班,普通版的感觉——而实际上,更多时候,大家关注的是学科中细粒度的知识点的掌握情况。
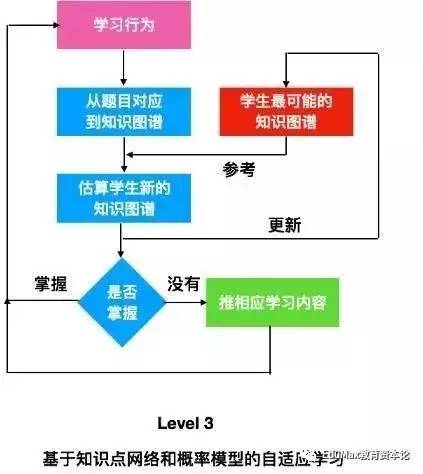
Level 3:基于知识点网络和概率模型的自适应学习
Level 2 只有难度等级的概念,现在我们要引入知识图谱的概念了。我们实际上是没有直接办法去测量学生的知识点掌握程度,我们只能倒过来从学生的做题情况,推断知识点的掌握程度。后面可能会涉及到一些数学公式,不会的同学可以选择性跳过。Level 3的内容比较多,我们分为多个部分来讲。
1、相同难度,单一知识点的题目
我们先解释一下,为什么学生的知识点要用概率模型来算。学生做对做错的最简单模型就是翻一枚不均衡的硬币,看正面朝上的分布。假如学生知识点的掌握度为p,p是0~1之间的一个数,意味着每做1道题,有p的概率做对。那么学生做了n道题,得零分的概率为(1-p)的n次方,得满分的概率是p的n次方,他最有可能做对的题目数是n*p。
问题是,没有人知道p为多少,我们倒过来只知道n道题里,有m道做对了。当n趋近于无穷的时候,我们几乎可以肯定p=m/n,但现实中,别说无穷道题,同一个知识点的题目让学生做20遍,学生就会受不了了。所以为了追求实用,我们必须牺牲一部分精度,我们可以认为n=0的时候,也就是我们对学生一无所知的时候,p应该是一个0~1的均匀分布,但是随着n的增加,p的分布应该如何改变呢?
实际上数学家们早已经告诉我们了,扔不均匀硬币的二项式分布的共轭先验密度函数(conjugate prior probability distribution)是beta分布(其多维版本叫做Dirichlet分布)。具体的公式和推导参见维基百科。
这里背后核心的思想是,同样是100%的正确率,同样难度的题,张三做了三道,李四做了20道,由于样本容量的不同,会导致知识点掌握度的置信因子不同。
2、不同难度,相同知识点的题目
接下来我们要考虑到,真实的题型,并不是都难度一样的,甚至说难度一个衡量指标,是远远不够的。举一个例子,题目一是1234*56789等于多少,填空题,题目二一个天体为水的密度,重量为1亿亿吨,请问这个天体是否是一个黑洞。前者其实难度是比后者小的,但是,由于前面是填空题,后面是判断题,其实后面的题目有50%的蒙对概率。为了能够对题目更好地建模,我们引入IRT(Item-response-theory)模型。
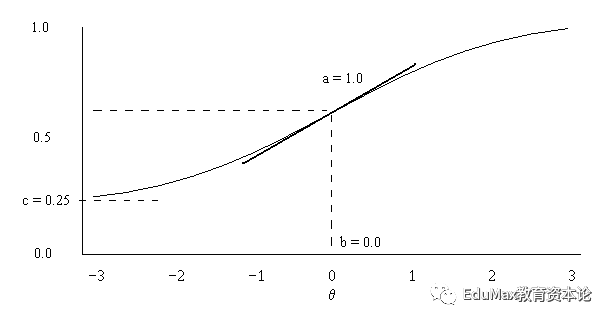
以上图是三个参数版本的IRT,其中a为区分度,b为难度,c为猜测可能性。横纵标里,值越高代表学生能力越强。c=0.25,意味着哪怕最差的学生都有25%的可能性做对,所以这道题目最有可能是一道4选1的单选题。b=0.0代表,这道题目的难度正好适中,如果b比较大,代表能够把特别优秀的学生和普通学生区分开,如果b比较小,代表这是一道送分题,如果这还做不对,大概是平时没有认真学习。区分度a,可以认为当区分度特别大时,这道题目是要么肯定就会,要么就是彻底不会,不存在中间地带。
IRT模型的初始化可以用老师来标注,但是后期只有有足够多的真实做题数据才反映真实的题目难度。通常来讲,一道题目被1000个不同的学生做后,参数就可以基本确定,当这道题被10000个学生做过后,会基本收敛,再来新的学生,参数变化会非常小。
在IRT的基础上,又出现了利用贝叶斯+HMM的BKT,还有基于深度学习的DKT等一系列算法,不管算法怎么演进,其核心目的在于通过做题情况估算学生真是的知识点掌握度。然而,刚才有一个重要的点被我们略过了,那就是,实际的题目,并不是只有单一知识点的,而往往可能同时对应多个知识点。这时候我们就要引入题目知识映射矩阵(q matrix)的概念。
3、一题多个知识点对应的情况
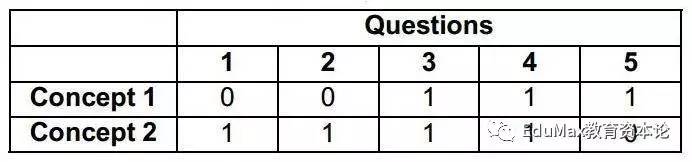
q matrix就是一个题目与知识点对应的矩阵,其中的值既可以是离散的0或1,也可以是连续的0~1之间的概率。Level 3级自适应学习的最大工作量之一就在于q矩阵的搭建,尤其是当知识点的粒度比较细的时候,所需要投入的人工成本非常大,就光初中数学一个学科,为百万道题目打标签,没有大几百万的经费是几乎不可能完成的。而哪怕在收到足够多的数据后,可以对q矩阵进行演化,做知识点的拆分和合并,但是在没有任何初始化的q矩阵,光有数据几乎是不可能空手套白狼变出一个知识图谱的。
到底应该怎样给题目打标签呢?这个过程一定要抛开狭义的课本上的知识点,而采用广义知识点(Knowledge Component)。广义知识点,除了章节以外,还应该包括策略,考察点,技巧,知识误区,甚至还有学生是否马虎大意,应用题的阅读理解能力如何。好的系统,可能会给选择题的不同选项都会对应不同的知识点,而填空题的情况还会更加复杂。
4、知识点相互关联形成知识图谱
知识点之间并不是孤立的。当学生做题之后,除了要更新题目所对应的知识点,还要以降低置信度+传播到相关知识点。这部分的算法并不复杂,真正难的是建立知识图谱。
知识点的关系,远比课本或教参中呈现的章节树复杂的多。章节树的结构,仅仅是做了包含关系,而且由于教材版本的不同,实际上会出现一个知识图谱与不同版本教材章节的映射网络。高中学习阶段,有的知识点会一次次地出现,然而每次地出现都是把过去的定义,特性推倒重来,可是到了高三总复习的时候,又要融会贯通,这些同类知识点,需要关联起来。很多团队做了知识的先后依存关系,但是忽略了,实际上有的时候多学的知识,不仅没有强化过去的知识,反而有可能会导致困惑,让过去的知识的掌握程度降低(例如英语里学完compose之后又学了comprise)。
5、考虑到时间的影响
一个学生做了100道知识点一样的题目,最终对了50道,这真的代表学生水平是0.5吗?实际上很有可能,前20道题,由于学生什么都不会,只对了2-3道,而后20道题,学生已经基本掌握了,可能一道都没错。我们要以变化的眼光去看待学生的发展,这就意味着,我们需要“遗忘”那些时间久远的事情。也就是我们需要一个滑动的窗口(sliding window),越遥远的行为数据权重越低。
还有一个时间的影响就是记性,随着时间的推移,学生遗忘的比例会越来越高。而最佳的复习时间,就是学生恰好要遗忘,却没有忘记的时候。自适应的复习算法,开源软件anki采用了supermemo的早期spaced repeatition算法,已经能够满足绝大多数的需求,也是多数背单词软件所采纳的算法。
终于讲完了,下面可以举例了。
6、数学的填空题,0.0035的科学计数法
比如学生回答:-0.35*10的3次方。那么最简单的办法是,系统评估这道题是一道简单题,说学生你的科学计数法基本功不行。但实际上如果是一名优秀的数学老师,他会发现,学生搞错了多个事情。一、科学计数法首位应该非零的数字。二、负号的位置学生搞错了。三、学生估计记得老师说过,从小数点往后数几位,指数应该放多少,而没有真正理解指数上的坐标的意思。
7、英语开放作文的发音和语法
发音的知识图谱比较简单,bit和bite混淆发音,那么lit和light混淆的可能性也非常大。甚至bed和bead都有可能因为元音长短因分不清楚而错误。这个在学生边读的过程中,就可以逐渐收集问题,并且推送相应课程。
语法的知识图谱就比较复杂了,同样是动词的过去式,规则动词就包括多种情况,不规则动词几乎每一个都构成自己一个知识点,过去式与过去分词搞混了又是另外一种情况。同样是冠词,a后面是元音是一种情况,但a user是一种特例,an hour是另一种特例,如果后面接的是地理位置,则更加混乱(the USA, 但不是the China)。英语的教研工作量一点都不比数学简单。
自适应做到这个地步,依然存在两大问题,一个问题是人工教研工作量耗大,做得越细越好,越困难。另一个问题是,只能解决客观题,对于证明题,简答题,完全没有办法做。而只有能够在解题步骤里做自适应,才是真正的终极解决办法。
Level 4:基于NLP和推理引擎的自适应学习
真正的AI级别的自适应学习,说的就是Level 4。如果拿自动驾驶技术来对比,这就是你可以撒手,不摸方向盘,不看路面,不听导航,在汽车里睡觉,汽车就会安全送你到你的指定位置。达到这个水平的自适应学习系统,可以做到拿到任何一道学科题目,就可以用多种策略得到正确答案(也就是最近高考机器人在比拼的事情),并且看到别人的答案时,判断答案是否正确。
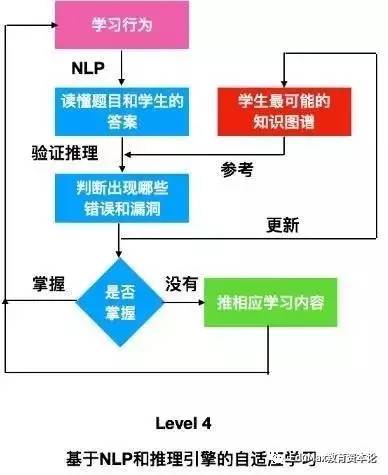
一个简单粗暴的想法是略过推理引擎,直接拿着几百万道题目做char-rnn,但很显然这个是不work的。可以认为答案就是如同程序代码一样的,是其内在逻辑的,然而目前char-rnn是根本没有能力生成任何有真实意义的代码,最多只能生成一些格式上看起来正确,但是没有任何含义的代码。
这件事情如果要做成,必须死磕推理逻辑。毕竟一道题目里,学生可能会出现的错误类型实在是太多了。例如:
- 推导错误
- 计算错误
- 关键步骤顺序不对
- 推导正确但原因不对
- 多次计算错误,但最终答案凑巧对了
- 用结论来“反证”结论
- 引入原本不存在的条件
- 冗余步骤
这个其实会像alphago一样,除了一个深度学习的价值和策略网络以外,也需要一个通晓逻辑的mcts,在数学运算这种场景下,一样也是需要“阅读理解”和“推理逻辑”两个部分。
所以,整个过程应该是:
- 【识别】将题目的题干和相关图片抽取成机器能读懂的条件
- 【逻辑】判断题目没有逻辑错误,确实有解(小红有三个苹果,小明有四个,请问小红多大了)
- 【逻辑】得出标准答案
- 【识别】如果学生是手写的答案,先做图像识别
- 【逻辑】如果是选择,填空,直接对比学生的答案
- 【逻辑】如果是大题,验证学生的推理过程是否完备,正确
- 【表达】判断学生出错的环节,不告诉完整答案,而只是给学生一个点拨性的提示
- 【表达】AI与人之间可以以一种对话式的界面
对比当下的扫题软件,学生哪里不会,去哪里抄答案。而这一的自适应学习系统,则更是,哪里卡住了,算错了,哪里小小地提醒一下。这种教学方法才是真正帮助学生成长和前进,当然这里也要防止部分学生利用提醒的机制不断刷最终答案。
1、英语作文AI批改
回到了Level 0的例子了,只不过再也不需要老师的参与,AI直接对词汇,短语,句式,语法,文章的逻辑性,结构,和文笔优美度给出了打分和修改建议。目前的AI对于前面几点(尤其国外的Grammarly公司)做得还可以,但是对于结构,逻辑,文笔,则是完全做不到。
2、一对一几何课
还是Level 0的例子,老师这回是真的面临失业了,全中国的每一个学生都配备了一个最厉害的AI老师,他能够针对性地解决你的学习问题,你做题并不需要在电脑上做,依然是笔和纸,但是他随时会提醒提示你,学习的过程由过去的很长时间才有反馈,变成了像游戏一样,很快就有反馈和进步。
结论,一旦出现了Level 4级别的自适应学习,从Level 0到Level 3级别的都会收到巨大的颠覆,毕竟都能自动驾驶了,自然就不需要单独的自动泊车技术。然而Level 4级别的难度非常高,无论是国内还是国际上都是在探索阶段。说实在,我这里没有展开说算法,因为连我也不知道具体算法该怎么做。至于在Level 4之后,未来几年会不会有没有像移植记忆等黑科技,目前我们就不得而知了。
本文转自微信公众号“EduMax教育资本论”,作者胡天硕,原标题为《寄在线教育创业者:揭秘自适应学习的背后原理(中)》。
1、本文是
转载文章,原文:
2、芥末堆不接受通过公关费、车马费等任何形式发布失实文章,只呈现有价值的内容给读者;
3、如果你也从事教育,并希望被芥末堆报道,请您
告诉我们。
来源:EduMax教育资本论
芥末堆商务合作:010-5726 9867



